欢迎在GitHub上关注FinTx开源金融系统:FinTx
]]>正确时金融系统设计的第一原则,不能保证正确其他原则都无从谈起。
对金融数据做到防篡改,防解析,防获取。默认不信任任何外来请求,数据…没有用户会愿意使用一个不安全的金融系统。
在国内的大环境下,对于有一定规模或有一定追求的金融公司,监管是不得不面对的问题。尤其是对互联网金融企业,针对一些国家,地方的互联网监管规范要求,如《互联网金融统计制度》和其他一些报送要求。
对所有的登陆,退出,请求,响应,业务处理,状态变更都要记录历史信息。方便风控,审计,追溯,定位。
领域(服务)内强一致性与领域(服务)间最终一致性相结合使用。系统间完善对账机制与业务监控。
无论服务内还是服务间,带超时的同步接口,查询/异步通知接口,撤销接口,配合定时补偿机制,结合使用。
保证服务调用的幂等性,业务处理的幂等性,不能保证幂等的地方需要请求去重,反馈去重,业务去重,对每一次变化,才能保证结果正确。
对每一次引起变化的事件,都要可识别,request要有RequestId,responseId,业务要有businessId…对有状态的业务要识别尽可能多的状态(有人提到MECE分析法,深以为然),并记录详细的状态迁移信息。作到一切事件,状态皆识别。
风控针对所有用户。不仅包括所有客户,也包括所有内部用户。
欢迎在GitHub上关注FinTx开源金融系统:FinTx
]]>在MySQL中单表自增主键是最高效的数据库索引,通过单库顺序自增或者多库设定不同的offset和increament来保证ID唯一性。但要在数据存入之后再从数据库取回,不便且面临网络可靠性的风险。默认性能不高单库很难突破千/s级别,多库情况下扩展困难。
优缺点:
MySQL并不像DB2 oracle有现成的Sequence特性。它是通过数据表+数据库函数方式实现的Sequence。同样也可以通过设定“current_value”和“increment”的方式多库生成。具体方法网上很多但是大部分都是有问题的,并发条件下会有重复ID。这里提供一个完整的方案 t_sequence.sql。默认性能不高也是很难突破千/s级别,多库扩展困难。但是可以使用获得的ID做基础,在本地附加本地顺序号进行二次分配提高性能。如获取1则在本地可分配[1000,1999]以此提高性能,实现会麻烦一些。
优缺点:
利用Redis单线程模型,获取自增ID。与数据库Sequence类似,也可通过使用不同初始offset和increment来扩展。不过引入了对Redis的依赖。默认但节点性能万/s-十万/s,同样可进行本地二次分配。
优缺点:
UUID有不同的版本,常见version 1 和 version 4。参见 RFC4122。UUID长度32字符。
UUID version 1 是基于时间 机器地址 本地序列号构造。
UUID version 4 是基于安全随机数算法构造的,是jdk默认的UUID实现。
优缺点:
64bit的long型分布式ID生成。ID中包含时间戳和自增序列。但是依赖于中心分配DataCenterID 和 Worker ID
优缺点:
MongoDB使用12byte数据结构,16进制编码24个字符。结构上与UUID version 1类似,但是做了一定的改进。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| time | machine | pid | inc | ||||||||
虽然由于inc采用随机数初始值大大降低了重复的可能性,但是由于machine采用hash值,理论上还是有可能产生重复ID。可能是考虑到inc随机数初始值的前提下可能性不大,且inc递增使时间回调有一定容忍性(回调n秒时峰值不超过2^24/(n+1)的前提下依能保证唯一),ObjectID也没有考虑时间回调的问题。一切系统放大到一定规模的时候,不太可能出现的问题就一定会出现。
优缺点:
fintx-identifer采用了类似ObjectId的方案,使用15byte数据结构,将machine扩展为48bit使网卡MAC地址作为机器唯一标识保证绝对唯一。处理了时间回调问题。并且采用64进制(Base64)编码字符串,将长度控制在20个字符。由于Base64的字符在UTF-8编码下只占1byte。UTF-8编码的20字符(20byte)唯一ID比UUID的32字符(32byte)减少37.5%。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| time | machine | pid | counter | |||||||||||
优缺点:
欢迎在GitHub上关注FinTx开源的唯一ID生成方案:fintx-identifer
]]>欢迎在GitHub上关注FinTx开源金融系统:FinTx
]]>| 账号 | 上期余额 | 余额 | 最终交易日期 |
|---|---|---|---|
| account_no | last_balance | balance | latest_trans_date |
在获取账户余额时,比较最终更新日期与当前日期,当前日期>=更新日期,则取余额,否则取上期余额。
在更新账户余额时,比较最终更新日期与当前日期。当前日期<更新日期(后详),则更新上期余额和余额。当前日期=更新日期,则更新余额。当前日期>更新日期,则设置上期余额=余额再更新余额,最后设置更新日期=当前日期。
由上可见,在双余额的条件下不太关心系统什么时候日切,只要按照交易系统传入的当前日期与更新日期做比较即可。
对更新余额的情况分两种–动账更新和批量更新。
动账更新时在每个账户需要进行账务处理时才更新账户余额,批量更新是每天日切之后对交易日期为昨日的账户统一更余额。动账更新的方式对系统资源占用更少但是对依赖于余额数据的批量来说会相对复杂,批量新会做大量无意义的处理,并且在日切后处理也无法完全保证账户持续可用(更新时要锁定虽然时间可能很短),但是对有依赖于余额数据的其他批量来说会更简单。FinTx开源的账务系统中选择了动账更新的方式,并且对余额获取提供方式提供了封装好的函数供全局调用。
当然账务系统由于其特定的领域特征,7X24的实现更复杂一些,但是原理相同。
| 账号 | 上期余额 | 上期借发生额 | 上期贷发生额 |
|---|---|---|---|
| account_no | last_balance | last_dr_trans_amt | last_cr_trans_amt |
| 余额 | 借发生额 | 贷发生额 | 最终交易日期 |
|---|---|---|---|
| balance | dr_trans_amt | cr_trans_amt | latest_trans_date |
这里也是一个简化模型引入了借贷发生额有时间再详细写,完整实现请先参考FinTx的开源账务系统。fintx-accounting
补充一份关于7X24服务实现的文档银行核心系统7x24方案参考,来源于网络,如有侵权请联系。
欢迎在GitHub上关注FinTx的开源账务系统:fintx-accounting
1 | CREATE TABLE `t_acctsn_custno_pkid` ( |
| CustNo | CustType | AcctSN | id |
|---|---|---|---|
| 0000001 | 00 | 0 | 1 |
| 0000002 | 00 | 0 | 2 |
1 | int concurrency = 5; |
1 | ------------------------ |
RC(READ COMMITTED)
PRIMARY) 某一行的X锁(table checkaccount.t_acctsn_custno_pkid trx id 336633 lock_mode X locks rec)PRIMARY) 某一行的X锁(t table checkaccount.t_acctsn_custno_pkid trx id 336632 lock_mode X locks rec)。这一行的内容为 1 0000002 00 15444。并且发生死锁时在尝试获取主键索引上(index PRIMARY) 某一行的X锁table checkaccount.t_acctsn_custno_pkid trx id 336632 lock_mode X locks rec)。这一行的内容为 2 0000001 00 5725.id bigint(20) NOT NULL AUTO_INCREMENT,)有关系。| Transaction1 | Transaction2 |
|---|---|
| (select acctSN+1 from t_acctsn_custno_pkid where custNo = ‘0000002’ for update) 1 对主键索引上所有行一行一行的加X锁 2释放custNo 为 ‘0000001’的行上的X锁保留custNo 为 ‘0000002’的行上的X锁 | |
| (select acctSN+1 from t_acctsn_custno_pkid where custNo = ‘0000001’ for update) 3对主键索引上所有行一行一行的加X锁,首先先对主键索引上custno为0000001的行加X锁 4 尝试获取主键索引上custno为0000002上的X锁 | |
| (update t_acctsn_custno_pkid set acctSN=’15445’ where custNo = ‘0000002’) 5对主键索引上所有行一行一行的加X锁,尝试获取主键索引上custno为0000001上的X锁 |
注3:根据前面的知识储备,及对死锁日志的分析,在上表的时序下满足了死锁产生的条件。
根据以上分析,绕了一大圈解决方法其实很简单 在custNo上加索引即可,其实custNo作为查询条件是应该有索引的,上线的同学疏忽了,造成了比较严重的线上故障,引以为戒。
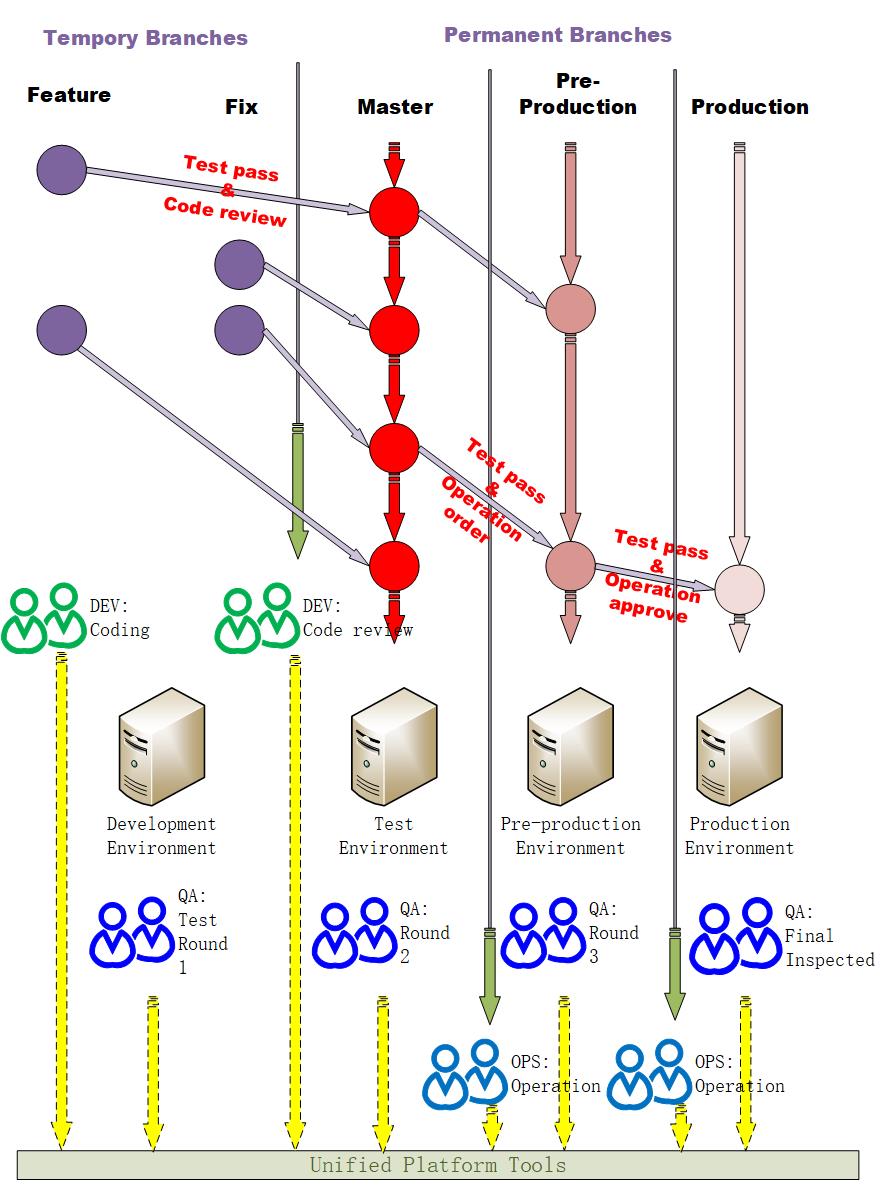
]]>完善的上线流程是系统稳定的重要保证.
很多中小型的初创公司使用Gitlab管理自己的代码,想必大家在项目的开发上线中也踩过了很多坑。作为一个过来人选择了Gitlab官方推荐的带有环境分支Gitlab flow(Environment branches with GitLab flow)的最佳实践作为基础,为研发、质量保证和运维团队制定了统一的上线流程。
做一些踏踏实实的事情.
Technology is tool, business is king.
技术是业务需求驱动的。用了再高深的技术,不满足正当的需求也是失败的项目。反过来说超出正当的需求而用了高深的技术,虽不一定是失败也是不理智的。用分布式系统为图书馆做个图书管理系统,这基本是只能在学校里发生的事情。当然也不排除是业务革命的可能,比如谷歌图书馆。但是世界上能有几个谷歌图书馆呢。
纵观国内的互联网金融乃至整个互联网行业,浮躁充斥着各个角落。由于高速发展带来的财富效应,资本聚集。即使遭遇寒冬,仍不能让人们冷静下来。在此感染下,催熟了一大批“高级工程师”,“架构师”。他们言必分布式语必微服务,张口cloud,闭口serverless。看了个例子就熟练XXX。“吹水”成了看家本领和最擅长的技能。找一家创业公司,拿着不菲的薪资,干着忽悠老板,忽悠投资人的事。他们从各种地方找各种人用开源软件七拼八凑,用他口中那些技术做了个每天个位数访问量的系统。殊不知,淘宝在2008年(PV2.5亿,会员5000万)之前还基本是一个单一系统。即便考虑技术的进步,PV过千万会员过百万之前还是省省吧。认真把基础的项目划分模块划分做好,分布式服务化都是水到渠成的事。即使是大型微服务化系统也是由一个个单一的节点组成,每一个节点本质都是一个单体系统。单一体系统都没做好就大干快上微服务无异于沙上建塔。其结果可想而知。问题百出,人肉硬扛,累跑运维是肯定的,没准还成本奇高。关键是最终才发现,业务没做好。当然公司最后如何与这些人是其无关,都可以怪公司业务没做好。当然失败的经验也是经验,技术当作成绩可以拿来忽悠下一家公司。
合适的才是最好的。是否合适取决于公司战略,业务,个人能力,团队的水平,和对技术的熟悉程度。对于创业公司来说,面临的问题与有成熟的大公司完全不同。用分布式,自建私有云,上规模的公司有高水平的研发团队,可靠的运维团队,几乎用不完的资源做后盾。这些公司业务完善稳定,技术改造同时不用面临业务的压力。但对创业公司而言,资源有限,人员有限,资金有限,团队水平参差不齐,互相不熟悉。在这种情况下,用最熟练的技术,快速实现业务需求,把业务流程,用户体验作好,精雕细琢。先让业务稳定下来才是首要目标。有了经过业务洗礼的可靠技术运维团队,有了一定的用户量做基础,才有可能支持系统进一步优化。
踏踏实实先做好业务的每一个细节。说来简单,可现实是残酷的。金融企业竟然连一个账务系统都没有,自己收了多少钱,该交多少税,最后赚了多少,哪些产品盈利,哪些产品亏损,一概不知道。拿企业最重要的资金收付来说,钱收的时候到没到,该收的够不够,多收少收怎么办,这些要么都是人工处理,要么根本不管对错。某银消费金融公司与下属企业上百万的款项成了糊涂账,并遭内外合伙骗贷造成巨额亏损。这种事情绝对不是个例。
罗马不是一天建成,好的系统是一步步迭代来的而不是设计出来的。“97%的情况下,过早优化是万恶之源”。有限的资源下,过度的技术设计必然导致业务设计不足,这是自寻死路。对业务需求,技术支撑不足才是初创阶段的主要矛盾。开始就按百亿估值做系统的创业公司,都死了。上来就按百亿级流量做分布式设计的架构师,都跑了。
希望FinTx能为大家提供一个探讨金融业务,架构,设计,技术,法规等话题的场所,并且提供一些能支持当下业务也能扩展未来发展的基础组件。大家一起做一些踏踏实实的事情。